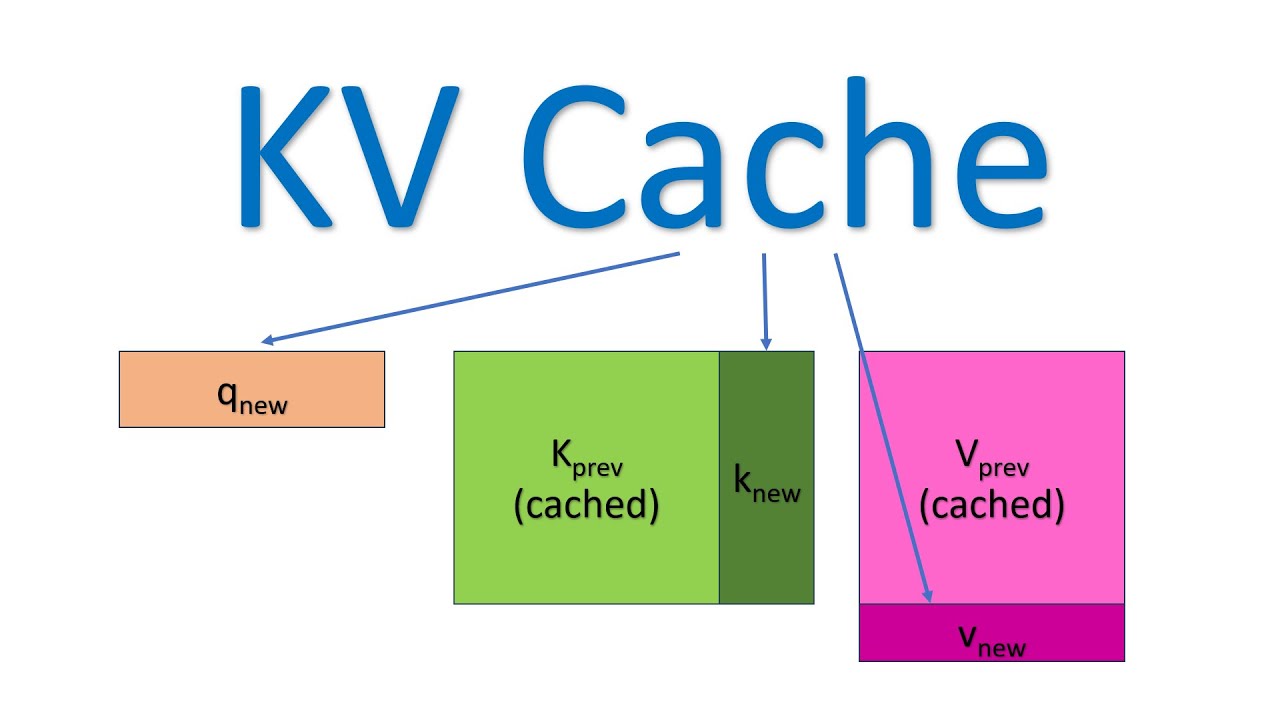
Self Attention is the important technique that makes Tranformers great. It allows the model to pay attention to different parts of the input sequence as it generates next token. It transform each input token into context vector, which combines the information from all the inputs in given text. KV caching is only present for decoder only models like GPT or decoder part of encoder-decoder models.
Context vector calculation involves three components – query, key and value.
We will look into details on how it is computed.
Lets first look into how we could load GPT2 in our system and then use that example to understand KV and KV Caching.
One interesting topic would be understanding the KV caching and understanding how privacy could impact it.
Self-attention is achieved by transforming input sequence into three vectors – query Q, Keys K and Values V. Attention mechanism calculated weighted sum of the values based on similarity between query and key vectors, which along with original input passed through feed forward NN produces the final result.
Loading GPT2 model
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
text = "She eats apple"
encoded_input = tokenizer(text, return_tensors='pt')
output = model.generate(encoded_input['input_ids'], max_length=10, num_return_sequences=2, num_beams=2, do_sample=False, temperature=0.0, pad_token_id=tokenizer.eos_token_id)
for i, sample in enumerate(output):
decoded_text = tokenizer.decode(sample, skip_special_tokens=True)
print(f"Sample {i + 1}: {decoded_text}\n")
This will generate two different samples of predicted text from GPT2 model. Sample 1 and Sample 2.
Sample 1: She eats apple pie, but he's not a
Sample 2: She eats apple pie, and I'm not sure
We can see the next text generated after “She eats apple” is “pie” we will look into how it could be calculated.
The important part in the generation process that we need to focus on is temperature=0.0, which means it will generate the same thing every time without providing probablistic result each time ie. the result will be deterministic to say. There are other ways to do it as well setting the seed as a static value, however this could be easier for now.
To understand the working of how model generated next tokens, we will have to get into the workings of various layers in the model. To do so we will have to return the attentions weights for the input texts to the model. Since generate() function only focuses on using the model to generate next prediction of tokens and not return those attention weights, we will be focusing on the forward passes method directly of the model instead.
# Forward pass on model including attentions
output = model(**encoded_input, output_attentions=True)
# attention weight - one tensor per layer
attentions = output.attentions
# attention tensor shape: (batch_size, num_heads, seq_length, seq_length)
# For simplicity, let's print the first attention layer and the first head
for layer_num, layer_attention in enumerate(attentions):
print(f"Layer {layer_num + 1} Attention:")
# layer_attention is of shape (batch_size, num_heads, seq_length, seq_length)
# Get the attention values for the first head
attention_head = layer_attention[0, 0, :, :].detach().numpy()
print(attention_head)
print()
(more…)